NLP课堂笔记
绪论
主要介绍了语言,文字,句法,语法。要知道NLP的定义,语言的起源无解(神授说,人创说),语言和言语的区别。语言的符号性(符号,能指,所指),语言符号的主要特点(线性,渐变性,稳定性,任意性),语言符号是音义结合的统一体,语言还有其他属性。
语言系统有组合关系(线性序列关系),聚合关系(联想关系)。语言系统的层级体系,分为符号层(句子,词,语素),音位层(音位)。语言具有社会性。
语言的两种分类:1.形态类型,词根语(汉语),粘着语(日语),屈折语(英语),编插语,2.句法类型,SVO(汉语,英语),VSO(日语),SOV(阿拉伯语)。
文字,起源于图画,分类为表意文字,表音文字,意音文字。汉语是一种词语文字,一种意音文字,语素文字,不是一种表意文字或象形文字。
语法。汉语的语法特点,1.语序和虚词是汉语的重要语法手段,2.句法同义现象,表达形式上的灵活性,2.诗词中的超语法现象是汉语中一种独特的语言现象。语法的定义(用词造句的规则)。语法单位有1.句子,2.词组,3.词,4.语素(一个汉字,也有两个汉字),根据语素在词中的不同作用分为词根,词缀,词尾三类。
句法分析,目的,有1.成分分析法,2.层次分析法,3.变换分析法。语言学是研究语言的学问。
先修基础知识
目录中有1.状态,操作和目标,2.状态图,3.状态图搜索,4.计算机上实现。状态图由点和边组成,搜索树,启发式搜索,贪心(爬山),A*/AO*算法。
语料库:语言样本与统计分析
语料库。语料库是语言数据的采样。从数据角度看自然语言,自然语言是一个系统,一个集合,自然语言的采样就是语料库。语料库语言学。
语料库的发展历史。早期(20世纪50年代中期之前),沉寂时期(1957~20实际80年代初期),复苏与发展时期(20世纪80年代以后,第二代语料库,LOB,TLF,ICE)。
语料库的种类1.共时语料库,2.历时语料库,或者1.通用语料库,2.专用语料库。典型语料库,1.布朗语料库(Brown),100万词,TAGGIT词性标注系统,2.英国国家语料库(BNC),一亿词。
语料库加工。文本处理:垃圾格式问题,大小写,标记化(token可以是一个词,一个数字或一个标点符号),句点(是否为句号),单撇号(切分,不切分),连字符(排版,连词,帮助区分正确的词组),相同形式表示不同的词语(同形异义词),词法(词干化,当性能指标是查询平均值时,对经典IR系统的性能提高没有帮助),句子定义(启发式算法,三种不是边界的情况),句子边界的研究(1.统计分类树,特征包括前后词的大小写和长度,不同词出现在句子边界的先验后验概率,2.前后词性分布,神经元网络,语言无关,3.最大熵系统),句子长度(新闻一般是23个词)。
语料库加工。格式标注:通用标记语言(SGML,XML是它的子集,HTML是它的应用),语法标注(Brown标注集,CLAWS1~5,Peen树库,ICE)。
语料库应用,简单的统计分析。Zipf法则,排在第50位的词出现次数大约是排在第150位的词出现次数的3倍,即排名和出现次数成反比(两边取对数就是线性),Mandelbrot公式(参数$B=1$,$\rho=0$就是Zipf法则)。搭配抽取1.频率方法,仅仅选择最频繁出现的二元组结果不理想,功能词较多,需要词性过滤器,2.均值和方差方法,能较好解决,因为某些搭配有距离,具体的方法是寻找带有低偏差值的词对,这意味着两个词通常会以大致相同的距离出现。
汉语自动分词
词法分析,1.分词,汉语的分词就是英语的token化的过程,2.词性标注,不是不可或缺的步骤,汉语中大多数词语只有一个词性,或者出现频次最高的词性远远高于第二位的词性,3.命名实体识别,属于词法分析中未登录词识别的范畴,通常包括实体边界识别,确定实体类识别,实体类主要识别三大类(实体类,时间类和数字类)和七小类(人名,地名,机构名,时间,日期,货币和百分比)命名实体。
分词。分词是正确的中文信息处理的基础。分词标准主要有5个。理性主义的分词方法,都使用预先建立的词典,依赖人的语言观察和经验直觉设计算法(长度和频率),启发式函数过于主观(假设,本质联系,贪心),有1.正向最大匹配,错误切分率为1/169,2.逆向最大匹配,错误切分率为1/245,3.双向最大匹配,最大匹配法存在分词错误则增加知识,局部修改,分词歧义则使用双向最大匹配,4.最短路径分词法,使用分词结果中含词数最少,好于单向的最大匹配方法,忽略了所有覆盖歧义,也无法解决大部分交叉歧义。最大词频分词法,构造词图,动态规划。
分词歧义可以分为有1.交集型切分歧义,链长,2.组合型切分歧义,交集型歧义:组合型歧义=1:22,或者1.真歧义,2.伪歧义,真歧义6%,伪歧义94%。
未登录词,分类1.专有名词,2.重叠词,3.派生词,4.与领域相关的术语,或者1.缩略词,2.专有名词,3.派生词,4.复合词,5.数字类复合词。识别难度1.较成熟,中国人名,译名,中国地名,2.较困难,商标字号,机构名,3.很困难,专业术语,缩略词,新词语。
分词质量评价,准确率(切分结果为分母),召回率(标准答案为分母),F-评价。
词法分析,Word Tokenization,Word Stemming(词干提取),lemmatization(词形还原)。国家分词规范,词,词组的定义,分词单位。由字构词,BMES,字标注,常用特征是字本身和词位(状态)的转移概率,工具有SVM,CRF。
汉语自动分词-N元(统计)语言模型
基于N元语法的切分排岐,利用了MM模型/过程的有限历史假设,仅依赖前n-1个词。一元文法等价于最大频率分词。二元文法,性能可以进一步提高,采用更大的N可以利用更多上下文信息,会有参数爆炸。等价类划分,即将一些历史划分为同一个等价类并且有相同的概率,则自由参数的数目会大大减少。更大的N对下一个此出现的约束性信息更多,有更大的辨别力,更小的N在训练语料库中出现的次数更多,更可靠的统计结果,更高的可靠性。
基于HMM的分词词性标注一体化模型。转移概率+发射概率(由Sentence,POS推导出来),二元文法计算。HMM的参数估计采用的是MLE。基于统计的词网格分词,利用词典匹配,列举输入句子所有可能的切分词语,并以词网格形式保存,用Viterbi算法找到一条权值最大的路径。
中文未登录词识别。分类1.命名实体,人名,地名,机构名,2.数字,日期词,货币等,3.商标字号,3.专业术语,4.缩略语,5.新词语。未登录词识别的依据有1.内部构成规律,如中国人名(姓,名,前缀,后缀,身份词,地名或机构名,的字结构,动作词),难点有高频词,内部成词,上下文组成词,人名地名冲突,可用姓名库匹配,2.外部环境,3.重复出现规律。未登录词识别的一般方法,将识别问题转化成标注问题BEIO,可以用HMM,ME,MEMM,CRF模型等进行标注。
语言模型,噪声信道模型(已知带有噪声的输出,想知道输入是什么),香农游戏(给定钱n-1个词或者字母,预测下一个词或字母,即从训练语料库中确定不同词序列概率)。N元语法基本概念:马尔可夫假设,等价类映射。二元文法也叫一阶马尔可夫链。
模型评价,实用方法是通过查看该模型在实际应用中的表现来评价统计语言模型,理论方法是交叉熵与困惑度。注意熵的计算方法。相对熵(KL距离)用于衡量同一事件空间中两个概率分布的相对差距,商的对数的和,交叉熵用来衡量估计模型与真实概率分布之间的差异情况,分布乘近似分布的对数的相反数的和,近似计算公式是模型对足够长词序列的概率取对数除N的相反数,在设计语言模型时,我们通常用困惑度来代替交叉熵衡量语言模型的好坏,计算方法为模型对足够长词序列的概率的负1/N次方。
词处理:统计语言模型(HMM)
分为马尔可夫模型,隐马尔科夫模型,HMM的三个基本问题及其计算。
马尔可夫模型,N元语言模型是MM的应用。一个系统N个状态,随时间状态转移,系统的时间t的状态由其在时间1,2,…,t-1的状态决定。离散的一阶马尔可夫链即只和t-1的状态有关,N个状态的一阶马尔可夫过程有N平方个,可以表示成为一个状态转移矩阵。也可以用有限状态机来表示一个马尔可夫模型。
隐马尔科夫模型。双重随机过程,不知道具体的状态序列,只知道状态转移概率,可观察事件的随机过程是隐蔽状态过程的随机函数。隐马尔科夫模型的组成部分有1.模型中状态的数目N,2.从每个状态可能输出的不同符号的数目M,3.状态转移概率矩阵A,4.从状态观察到符号的概率分布矩阵B,5.初始状态概率分布$\pi$。所以一般HMM记为一个五元组,为了简单有时也将其记为三元组(只包含3,4,5)。
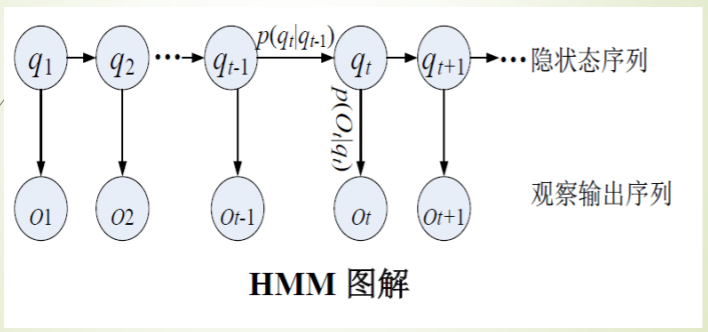
HMM的三个基本问题及其计算。1.估计问题,给定观察序列和模型,求解观察序列的概率,2.序列问题,给定观察序列和模型,求解最优的状态序列,3.参数估计问题,给定观察问题,用最大似然估计求模型的参数值。观察序列符号为O,状态序列符号为Q。
估计问题(解码问题),用动态规划,前向算法符号$\alpha_t(i)$,已经输出了t时间的观察序列,后向算法符号$\beta_t(i)$,已经输出了t+1时间的观察序列,注意转移为求和。
序列问题,维特比算法,对最优有两种理解1.对每个时刻t找到状态最优,找到argmax的$\gamma_t(i)$相当于局部最优,每个状态单独最优不一定整体状态序列最优,可能两个最优状态之间转移概率为0,2.全局最优,定义维特比变量$\delta_t(i)$,转移为$\delta_{t+1}(i)=max_j[\delta_t(j)a_{ji}]b_i(O_{t+1})$,整个算法分为四步,初始化,归纳计算,终结,路径(状态序列)回溯。上面三个算法的时间复杂度都是$O(N^2T)$。
参数估计,EM算法。迭代收敛至最大似然估计。每次需要计算t时刻从状态i转移到状态j的期望次数,然后计算t时刻从状态t转移出去的期望次数(E步骤),然后计算$\pi_i$,计算下一次迭代的$a’_{ij}$和$b’_j(k)$(M步骤)。
句法分析-CFG
句法分析定义,1.判断单词串是否术语某个语言,2.如果是,则给出其(树)结构,对应的两个子问题是语言体系的形式化描述和语言结构的分析算法。句法分析任务1.判断语言,2.消歧,3.最有可能的结构。
语言体系的形式化描述,三种方法1.穷举法,2.语法/文法描述,3.自动机法。形式语言通过四元组(非终结符,终结符,重写规则,句子符/初始符)来表示。有1.正则文法,2.上下文无关文法,3.上下文相关文法,4.无约束文法。自然语言通常使用上下文无关文法(CFG)来描述。
语言结构的分析算法。有自顶向下(预测),自底向上(归约)两种控制策略,深度优先搜索和广度优先搜索都适用两种控制策略,自左向右和自右向左或者中间是常用的扫描策略。当语言没有二义性时(或者句子没有二义性)可以采用确定性算法。
移进-归约算法。使用堆栈,有四种操作1.移进,2.归约,3.接收,4.拒绝。两种冲突1.移进-归约冲突(一般先归约),2.归约-归约冲突(一般按照规则顺序)。用断点信息来回溯。移进-归约算法是一种自底向上的分析算法。
线图。有三个部分chart,agenda,active arc。过程大致是取agenda,匹配规则,确认边,检查active arc(两种)。优点是简单,容易实现,弱点是效率不高,算法复杂度为$O(N^3)$,严重依赖句法规则质量,难以区分歧义结构。
句法分析-PCFG
CFG有缺陷1.规则太多,分析过程复杂,2.无法在大量结果中进行消歧并选择最有可能的分析结果,3.手工编写的规则一般带有一定的主观性,4.写规则需要大工作量,不利于移植。基于规则的句法分析有许多局限,统计句法分析中较好的有PCFG。
一个PCFG包括1.终结符集合,2.非终结符集合,3.指定的初始符,4.规则集合,5.规则概率之和,一个结构的概率就是结构所用的规则的概率的乘积。PCFG假设满足三个条件1.位置不变性,2.上下文无关性,3.祖先无关性。
PCFG句法分析模型使用CYK算法。大致是在三角图中不断合并语法结构,同一范围同一结构只保留概率最大的那个。用于剪枝的策略有beam search(集束搜索),是一种启发式图搜索算法,使用BFS,每次扩展下一层结点的时候只保留根据启发式函数算出的最好的beam width个结点,由五部分组成1.启发式函数h,2.beam width,3.BEAM用于保存下一层扩展的结点,4.set保存启发式函数的输入空间,5.hash table用于保存所有已经访问过的结点,算法一共有四步1.开始结点,2.BEAM扩展到set,3.选beam width个到BEAM,记录hash table,4.到找到目标结点时结束或者hash table已满或BEAM为空。
PCFG的来源是宾州树库(宾州大学语料库)。Penn Treebank包含了一个数据集WSJ,有训练集,开发集,测试集。目前比较广泛的句法分析器评价指标是PARSEVAL测度,三个基本的评测指标1.精度,2.召回率,3.F值(一般用F1测度)。著名的句法分析器,Collins Parser,Bikel Parser,Charniak Parser,Oboe Parser,Berkeley Parser,Stanford Parser。PCFG的优点1.减少分析过程的搜索空间,2.对概率较小的子树剪枝,3.可以定量比较两个语法的性能。PCFG的缺陷1.结构相关性(同一个非终结符在不同位置的推导概率不一样,不同产生式的推导不独立),2.词汇相关性(句法规则的推导依赖于具体的单词)。
PCFG总结1.句法规则来自标记树库,2.自然语言是上下文相关的,3.PCFG是一个非常粗糙的概率模型,不一定适合描述自然语言。
语义计算初步-词义消歧
形式化语言不足以描述自然语言。句法关系是语法形式表现出来的语法单位的组合关系,语义关系是对词所反映的事物或现象之间现实关系的概括,是实词跟实词之前的语义联系。语义计算的任务是解释自然语言句子或篇章的意义。
语义计算的经典框架有1.格语法,2.语义网络,3.概念依存。义项,词典中的表示,语义学中或称义位(更小的单位叫义素)。义位之间的关系有上下义关系和整体部分关系,一个语言所有的义位集合是该语言的最大语义场。
重点处理多义词。语义歧义是指很多词语具有几个意思或语义,如果将这样的词从上下文中独立出来,就会产生语义歧义。多义词计算主要是针对多义词的判别,需要寻找具有区别意义的上下文,有不同的WSD方法。WSD需要解决三个问题1.判断一个词是不是多义词,2.表示不同的义项(前两个是WSD所需的基础资源),3.确定一个合适的义项。WSD需要的基础资源有1.传统的语文词典,2.义类词典/同义词词典,3.标注好义项的语料库。
基于知识库的词义消歧。主要有1.基于词典释义的WSD,对于多义词有若干义项S,每个义项有一个释义D,每个释义是一组出现在该释义中的词a,多义词在一个具体的上下文C中出现时,前后有一些特征词W,每个词也可能有多个释义,这些词的释义集合的并集和a的交集能够形成最大集合对应的那个释义就是该多义词的义项,2.基于义类词典的WSD方法,有三步,对于每个义类收集包含这些义类的上下文,对上下文统计计算每个义类的特征词的权值,判断某个具体的语境中出现的多义词所属的义类,可以理解为对一个多义词所处语境的“主题领域”的猜测。
基于统计的方法。主要有1.基于互信息的WSD方法,需要找到示意特征,采用Flip-Flop算法,分两类(R,Q)然后使互信息最大,2.基于Bayes判别的WSD方法,需要标注好词义的语料库,然后训练出“语境”与词义之间的依赖关系,得到“词义知识库”,最后对输入的句子中的多义词计算可能性最高的义项。
WSD解决的两个问题1.如何确定用于词义排岐的可靠知识,2.如何低代价,高效地,大规模地获得这样的知识。WSD研究的困难1.词义缺乏明确的定义,2.搭配并不能完全确定一个词的意义,3.词义是相互依赖的,4.对WSD系统的评价困难。另一个解决WSD的思路是将词义歧义在任务整体模型中解决,需要更直接更明确的语义表示和任务整体模型具备更强大消歧能力。
篇章(内)的计算
主要介绍了语篇分析简介,指代和指代消解,衔接和连贯,篇章表示和相似度计算。
语篇是前后意义关联的句子序列。
指代现象来源语言的表达追求“经济”与“变化”。指代是简略提及某一实体的一种手段,目的是期望能消除该提及从而确定实体的身份。有六类指称表示1.不定名词,2.有定名词,3.人称代词,4.指示代词,5.one指代,6.0型指代。指代一般包含两种情况1.回指(前指),2.共指,可独立于上下文。
指代消解。有回指消解和共指消解。可用的方案有1.中心理论,2.分类方法(机器学习等)。中心理论,语篇由不同的语段组成,中心是联系不同语段的实体。有1.前看中心$C_f$,一句话中的所有实体,有序列表,主语大于直接宾语大于简介宾语大于其他实体,2.回看中心$C_b$,上下文关注的中心,是前一个语段出现并且排序最靠前的中心,3.优选中心$C_p$,当前语段关注的实体,前看中心中排序最靠前的实体。基于中心理论的消解方法是用各种约束条件过滤之后利用连贯性来评级。确定连贯性的高低通过表格中的评价来确定。基于分类(ML)的指代消解,利用机器学习的方法建立分类器,选择对共指消解产生影响的特征,主要包括两者的距离,字符的匹配程度,单复数一致性,性别一致性,语义类一致性,是否是别称等等。指代消解的应用有机器翻译,文本摘要,实体链指(基本上文本处理相关的一切应用都需要用到指代消解)。

衔接(Cohesion)和连贯(Coherence)。语篇应该有语义相关性和形式上的关联。衔接强调词之间的联系,五种衔接关系有1.指代,2.替换,3.省略,4.连接,5.词汇衔接(复现关系,搭配关系),连贯强调整体上表达某种意义(逻辑关系),连贯关系有1.结果关系,2.解释关系,3.平行关系,4.细化关系,5.时机关系,可以基于连贯建立篇章层次结构(树结构)。
修饰结构理论RST。通过修饰结构表示语篇结构,由修饰关系刻画,关系的双方分别是Nucleus和Satellite,一共23种关系,分为二元关系和多元素关系,语料库有RST Discourse Treebank。
篇章表示和相似度计算。向量空间模型,每个词为一个维度,将一个文本文件表示为标识符向量的代数模型,将两个文本都表示为向量之后,就可以进行相似度的计算。有余弦相似度。基于句子的语篇表示有分层的语篇表示方法,具体是1.通过某种方法得到句子的编码表示,方法有向量空间模型,N元语言模型,循环神经网络等等,2.对句编码进行组合,得到篇章表示,方法有TextRank,卷积神经网络,循环神经网络。
篇章(外)的计算。主要有1.文本分类,2.文本聚类,3.自动文摘,4.文本生成。
机器翻译
主要讲了机器翻译概述,传统机器翻译方法,经典统计的机器翻译模型,基于短语的翻译模型,线性对数模型。
机器翻译概述,机器翻译是用计算机把一种语言(源语言)翻译成另一种语言(目标语言)的一门学科和技术。有1.草创时期,W.Weaver发表了备忘录,2.低谷时期,3.复苏和繁荣时期,4.当前现状,使用神经机器翻译模型。机器翻译研究内容有1.文本翻译,2.文本对齐,3.质量评价,4.译文后编辑。难点在于1.歧义和未知现象(新词和专有名词),2.机器翻译不仅仅是字符串的转换,还有知识,3.机器翻译的解不唯一且没有同一的标准。目前是协助而非替代。
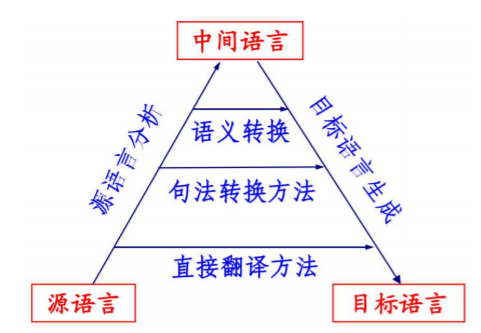
传统的机器翻译方法。有1.直接转换方法,直接翻译成目标语言译文,必要时进行简单的词序调整,2.基于规则的翻译方法(基于转换的翻译方法),对源语言句子进行词法/句法/语义分析,源语言句子结构到译文结构的转换,译文句法结构生成,源语言词汇到译文词汇的转换,译文词选择与生成,优点是译文结构与源文的结构关系紧密,弱点是工作量大,不利于扩展,3.基于实例的翻译方法,将输入语句与事例相似度比较然后生成翻译结果,需要大规模事例库,优点是对语法要求不高,弱点是相似性难以把握,口语句子结构比较松散,难以处理事例库中没有记录的陌生的语言现象,事例检索的效率较低。
经典统计的机器翻译模型,基本原理是噪声信道模型,对源语言句子和目标语言句子用贝叶斯公式,变成语言模型和翻译模型的乘积的最大化参数。有三个关键问题1.估计语言模型概率,2.估计翻译概率,3.快速有效地搜索T使得两者乘积最大。估计语言模型可以使用N元语言模型。翻译概率则有1.基于词的翻译模型,2.基于短语的翻译模型。
IBM模型是基于词的统计机器翻译模型,IBM模型1通过计算词的翻译概率来计算$p(e,a|f)$,其中$t(e|f)$是利用EM算法计算,EM算法大致思想是通过迭代计算直到收敛,E步计算$p(a|e,f)$,M步利用$c(e|f;e,f)$计算$t(e|f;e,f)$,引入词对齐的问题,通过EM算法学习词对齐,缺点是无法刻画翻译过程中的重排序,添词,舍词等情况,IBM模型2引入了绝对对齐,即对齐概率分布$a(a_j|j,m,l)$(满足约束条件)的概率,由英语句子e生成法语句子f的过程是1.根据概率给f选择一个长度m,2.对于m中的每个j,根据概率分布$a(a_j|j,l,m)$从l中选一个值给$a_j$,3.对于每个j,根据概率选择一个法语单词$f_j$。IBM模型3引入了繁衍率。
基于短语的统计机器翻译模型,注意到此处的短语的概率不等同于语言学上的短语,翻译过程是1.原文,2.短语划分,3.翻译,4.调整顺序。需要1.词对齐,2.抽取短语对,列举源语言所有可能的短语,根据对齐检查相容性,3.短语对打分,为短语翻译分配概率,可以按照相对频率打分,也可以引入短语的词汇化翻译概率,利用IBM模型1训练得到词语翻译表计算双向的词语翻译概率。
统计机器翻译的对数线性模型。对数线性模型是一个对信源-信道模型更具一般性的模型。假设e,f是机器翻译的目标语言和源语言句子,$h_i(e,f)$是e,f上的M个特征,$\lambda_i$是与这些特征分别对应的M个参数,则翻译概率直接利用指数和进行模拟。最佳译文e就是最大化概率的e。Och的实验(利用线性对数模型)1.将信源信道模型中的翻译模型换成反向的翻译模型,2.调整参数$\lambda_1$和$\lambda_2$,提升了系统性能,3.引入了其他一些特征(句子长度特征WP,附加的语言模型特征CLM,词典特征MX)。线性对数模型的优点1.大大扩充了统计机器翻译的思路,2.特征的选择更加灵活,可以引入任何可能有用的特征。
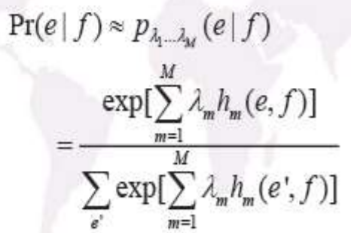
统计机器翻译的发展有两条主线的进展。框架模型的进展1.信源信道模型,2.对数线性模型。翻译模型的进展1.基于词的模型,2.基于短语的模型,3.基于句法的模型。
语言自动生成
NLG,是一种从机器表示系统(如知识库或者逻辑形式)生成自然语言的NLP任务。
NLG的发展历史,有1.模板生成技术,根据用户输入信息代替模板中的变量,2.模式生成技术,基于语义学中的修辞谓词来表达文本结构,将文本表示成结构树形式,3.短语规则扩展技术,基于RST,将文章的各个组成部分按一些特定的关系按照一定的层次内聚在一起,有两种模式,nucleus-satellite和multi-nucleus,4.属性特征生成技术,输出单元与特定的属性特征相连,在生成过程中对每个信息增加对应的属性特征,确定输出结果。
NLG数据集,PIL,SumTime Meteo等,NLG现有系统,ASTROGEN,CLINT,NLGen等。
NLG应用,论文写作,摘要生成,自动作诗,新闻写作,报告生成,百科写作等。
数据到文本的生成技术,系统框架有三阶段流水线模型1.信号分析模块,2.数据阐释模块,3.文档规划模块,4.微规划与实现阶段。应用有天气预报,空气质量,财经数据,医疗诊断数据,体育数据。
文本到文本的生成,对给定文本进行变换和处理从而获得新文本的技术。对联自动生成,特点有1.上下具有相同长度,2.音调协调,3.相同词性和特点,4.内容相关但不重复。自动生成的步骤1.使用Phrase-based SMT Model生成出N-Best候选,类似对数线性模型,采用的特征函数有Phrase translation model,Inverted phrase translation model,Lexical weight,Inverted lexical weight,下联的语言模型得分,2.基于语言学的筛选,3.基于其他特征重排序。生成对联的评价方法有BLEU。诗句自动生成,步骤是1.基于模板生成第一句,2.SMT model生成四句诗。
知识图谱
介绍了1.自然语言处理需要知识,2.什么是知识,3.知识的表示,4.知识的图谱,5.知识图谱的应用,6.知识图谱的构建。
自然语言处理需要知识。在机器阅读理解/问答系统主流系统框架中需要知识。知识是计算的依据,可以填补数据上的空白,从NLP到NLU需要更广泛的(世界)知识。
知识的概念。概念分层1.噪声,2.数据,3.信息,4.知识,5.元知识。知识是有关信息关联在一起所形成的信息结构。
知识的表示。有1.命题逻辑表示,有很强的局限,如原子命题需要进一步细分,不同原子命题之间有内在联系,2.一阶谓词,由命题,逻辑联结词,个体词,谓词与量词等部件组成的形式语言符号系统,有一定的表达和推理能力,但是效率低,知识表达能力差,组合爆炸,3.产生式表示,4.框架表示,注意备注,5.语义网络,有四种关系,子集/个体/属性/数量,6.本体论,是关于存在或事物本身的研究,主要研究如何分类事物和描述事物,一个“存在”的层次实例是树状的义原层级结构,本体当代的定义是共享概念模型的明确的形式化规范说明,构造本体有五条规则1.明确性和客观性,2.完全性,3.一致性,4.最大单调可扩展性,5.最小承诺。
知识图谱。主要关注知识的表示,用结构化三元组存储现实世界的实体及实体间关系。三元组(实体集合,关系集合,知识图谱中三元组的集合)。三元组描述特定领域的事实,由头实体,尾实体和描述这两个实体间的关系组成,有些关系称为“属性”,则为实体成为“属性值”,可以以同一的方式体现知识定义和知识实例两个层次共同构成的知识系统。有语言知识图谱,语言认知知识图谱,常识知识图谱,领域知识图谱,百科知识图谱。
知识图谱的应用,智能搜索,智能问答,智能推荐,决策支持,语义理解。
知识图谱的构建。分为1.知识体系构建,2.知识获取,3.知识融合,4.知识存储。知识体系的构建指采用什么方式表达知识,构建一个本体对目标知识进行描述(知识类别体系)。资源描述框架(RDF),资源是指能够使用RDF表示的对象,互联网上的实体,事件,概念等,谓词是指描述资源本身的特征和资源之间的关系,或者属性,陈述包括三个部分,即RDF三元组,由主体,谓词,宾语构成,如“首都(中国,北京)”,首都是关系,中国是头实体,北京是尾实体,“国籍(姚明,中国)”,国籍是属性,姚明是头实体,中国是属性值。知识获取的来源有1.结构化数据,2.半结构化数据,3.非结构化文本数据,需要实体识别,实体消歧,关系抽取,事件抽取(从描述事件信息的文本中抽取用户感兴趣的事件信息并以结构化形式呈现)。知识融合,对不同来源,不同语言或者不同结构的知识进行融合,分类可以按融合对象分类1.知识体系融合,2.实例融合,或者按融合类型分类1.竖直方向,2.水平方向,可以从语境信息中获取关键信息,提高融合精度。知识存储,目前知识图谱大多基于图的结构,可以用1.RDF格式存储,三元组形式存储数据,缺点是搜索效率低,可以用六重索引,2.图数据库Neo4j,优点是完善的图查询语言,缺点是数据更新慢,大结点处理开销大,改进是子图筛选,子图同构判定。
实验数据与结果分析
机器学习基础和数据分配。机器学习从大量实例中学习经验,然后使用经验去解决新问题。数据集是大量实例(样本)组成的集合,训练(学习)是从数据集中学习模型的过程,所使用的数据集称为训练集,测试(预测)是使用训练好的模型对未知实例进行预测的过程,数据集称为测试集。机器学习主要有分类任务和回归任务。机器学习的目标是泛化,一种恰当的学习方法不能过拟合也不能欠拟合,验证集用于观察泛化误差。验证集的构造方法有1.留出法,2.交叉验证法,k折交叉验证法,留一法,3.自助法,对n个样本组成的数据集D进行有放回抽样,抽出的样本放入D‘,至D‘中包括了n个样本位置,大概有36.8%的数据没被采样到D’中,使用D‘作为训练集,抽样方法有随机抽样方法(简单随机抽样,分层抽样),系统抽样,整群抽样。
性能评估。准确率和找回率,准确率是模型判定为正的样本中实际有多少真的为正,召回率是实际为正的样本中模型判别出了多少。准确率和召回率之间存在矛盾,有P-R曲线。不同任务中对准确率和召回率有不同的偏重。综合准确和召回有1.AUC,P-R曲线下的面积,计算困难,2.平均准确率与召回率,得到F值,F1值是准确率与召回率的调和平均数,$F_\beta$是加权调和平均,与算数平均,几何平均不同,调和平均更注重较小值。还有一些没有“标准答案”的任务,使用人工评测作为最精确的评价标准,以BLEU为例的评价指标,其核心设计前提都是使得评价指标的判断与人工判断尽量相似,在尽量近似人工评价的前提下,设计这些评价指标,可以大大减少模型评估的耗时,同时避免人类主观想法带来的标准不统一。
结果分析。特征贡献度分析,可以使用ablation study。不同的特征之间可能不是简单的叠加关系。判断一个模型好于另一个模型可以使用统计假设检验,可以采用符号检验和Wilcoxon符号秩检验。
基于字符相似度的机器翻译自动评价技术-BLEU
评价机器翻译的结果的质量。可以使用修饰过的N元准确度,一元更加倾向于忠实度,更长的N元匹配倾向于流利度。可以用BLEU指标计算,其中的$p_n$就是匹配的结果。
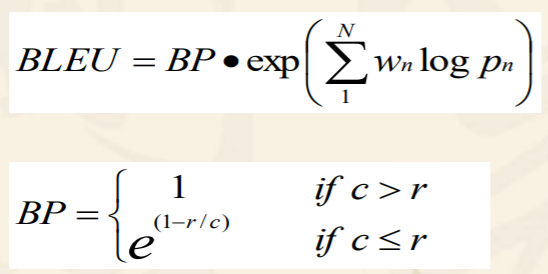
对话系统
主要讲了1.对话系统的应用,2.对话系统的分类,3.对话系统的评价,4.对话系统的道德问题。
对话系统的应用,有1.基于手机的个人助理,2.车载对话,3.机器人交流,4.心理健康临床诊断,5.闲聊。
对话系统分为1.聊天型,2.任务型。
聊天型。有1.ELIZA,2.PARRY,3.ALICE,4.CLEVER,5.Microsoft Little Bing。聊天型对话系统的架构有两种1.基于规则的,行为模式(Eliza),或者加上心理模型(Parry),2.基于语料库的(大规模聊天语料库),使用信息检索和神经网络编码和解码。聊天型对话系统的主要功能有1.娱乐,2.医疗。
基于规则的聊天系统。Eliza是1966年诞生的,假装对真实世界一无所知,匹配pattern并使用transform来回答,并且优先匹配特殊的关键字,同时有缺省回复,也可以用模式匹配来实现记忆,并且具有其他特点1.规则可以推出词的类型,2.同一个谈话中不重复使用同一规则,3.一些基础的转换在输入的时候执行。Parry系统在1971年诞生,和Eliza有一样的模式-回复结构,还有控制结构和语言理解能力以及一个心理结构(Anger,Fear,Mistrust),人设是一个28岁的单身男青年,邮局职员,没有兄弟姐妹,独自生活,Parry系统有许多复杂的IO规则,每个句子被映射成一个概念。
基于检索的聊天型对话系统。有Cleverbot,Microsoft XiaoIce,Microsoft Tay。基于检索的聊天机器人的两种架构1.检索与问题最相近的问题的回答,可以使用余弦相似度,2.返回和问题最相近的问题。也可以使用其他特征(不仅仅是问题),比如用户特征等,或者使用非对话文本。
神经网络聊天机器人。将生成回答看一个将用户之前的主动转到系统的主动上的任务。将用户1映射到用户2的回答上,使用Seq2Seq架构。
任务型。主要是基于框架的任务型对话系统,基于领域本体论。使用一个或者更多个框架,每个框架是slots的集合,每个slots有一个值(需要一个值),slot的类型可以很复杂。GUS是1977年诞生的基于框架的对话系统。基于框架的对话系统的控制多采用有限状态对话管理,系统完全控制与用户的谈话,这种叫做single initiative,为了更加像真实对话,需要引入通用规则,即用户可以任意说命令,GUS结构是混合initiative,用框架的结构引导对话。更好的是使用NLU来填补对话slot,步骤是1.领域分类,2.意图确定,3.填补slot,填补slot的方法有基于规则的Slot填补,需要1.数据结构,2.规则集合,包括条件和动作,也可以使用机器学习来填补slot,也是确定领域和意图,也可以使用IOB标注,B-领域名,I-领域名,通过一个序列模型来完成序列标注。
评价。两种评价方式1.对一个句子的slot错误率,2.端到端的评估。
对话系统的道德问题。机器学习学习到的语料库,隐私,性别平等。
神经网络基础
线性分类方法与神经网络。softmax分类方法,使用softmax函数得到概率,使用交叉熵作为损失函数,计算哈密尔顿算子作为调整策略,softmax只能给出线性分类边界,分类能力受限。神经网络分类器可以表示更复杂的函数,得到非线性分类边界。
$$
softmax(f_y)=p(y|x)=\frac{exp(f_y)}{\sum_{c=1}^Cexp(f_c)}\
J(\theta)=\frac{1}{N}\sum_{i=1}^N-log(\frac{e^{f_{y_i}}}{\sum_{c=1}^Ce^{f_c}})
$$
神经元与神经网络的表示。隐藏层的神经元$h_{w,b}(x)=f(w^Tx+b)$,激活函数sigmoid函数$f(z)=\frac{1}{1+e^{-z}}$,也是一个逻辑回归单元,一个神经网络相当于多个逻辑回归单元在同时运行。损失函数会指导中间隐藏层变量的取值,以便更好地预测下一层的目标,f必须为非线性函数是因为让神经网络有非线性变换。
神经网络在NLP中的应用示例。基于二分类的地名识别。使用max-margin损失函数,即最小化$J=max(0,1-s+s_c)$,其中$s$是正例样本的分数,$s_c$是负例样本的分数,可以使用随机梯度下降(SGD)来调整参数,完整的优化目标函数是,对于每个正例,构造多个负例,然后对所有窗口的$J$求和。随机梯度下降采用更新公式$\theta^{new}=\theta^{old}-\alpha\nabla_\theta J(\theta)$,其中$\alpha$为步长或者学习率。计算梯度的方法有两种1.手动,多变量求导,2.后向传播算法。
神经网络中导数的计算。雅可比矩阵,链式规则。
计算图与反向传播。前向传播之后进行反向传播。注意下游等于本地乘上游,当有多个正向输出时把结果相加即可。
总结。神经网络是一种非线性分类的方法。神经网络参数的优化可以采用随机梯度下降(SGD)的方法,SGD中的参数更新需要用到反向传播方法,反向传播是沿着计算图递归地使用链式法则。
深度学习简介
深度学习的兴起,深度学习是机器学习的一部分。DNN和CD-DNN-HMM在语音技术中有重要应用,CNN在图像技术中有重要应用,神经概率语言模型和基于语言模型的RNN在自然语言处理中有重要应用。
常用的深度学习模型有1.DBN深度置信网络,2.CNN卷积神经网络,3.RNN循环神经网络,其中有递归神经网络,4.注意力机制。
CNN,1984年提出神经认知机模型,CNN需要卷积和池化,具有W核矩阵,W矩阵中各个元素的值是我们进行模型训练的时候要训练的参数。
RNN递归神经网络将同一套参数,按照某种拓扑序列递归地应用到数据上,以对数据越其结构,或对给定结构的数据学习其表示,最早用来学习逻辑表达式,近年来用于NLP中的句法分析,语句表示等。
RNN循环神经网络最早的雏形是Hopfield于1982年提出的Hopfield神经网络(一种结合存储系统和二元系统的神经网络,保证了向局部极小的收敛,但收敛到局部极小值,而非全局极小的情况也可能发生,Hopfield网络提供了模拟人类记忆的模型),循环神经网络,不同时刻共享隐层权重,但具有时间上的循环,循环神经网络的一般架构的基本特点是结构本身存在自循环,为处理序列形式的数据而设计,针对序列数据具有强大的建模能力,训练过程常用BPTT,问题有1.如果初始化的权重矩阵偏小,反向传播的过程中,序列早期输入的梯度就会指数级的减小,以至于消失(梯度消失),解决办法是:LSTM(长短时记忆),GRU(门限循环神经元),2.如果初始化的权重矩阵偏大,当序列过长时,反向传播的过程中,不同时刻的梯度叠加,会使得参数的梯度指数级增长,以至于溢出(梯度爆)。LSTM,长短时记忆循环神经网络,核心思想是设置记忆单元,遗忘门,输入门,输出门,门限循环单元,核心思想是去掉了显式的记忆单元,设计了重置门(短时记忆的贡献)和更新门(当前短记忆和之前记忆的重要性,起到了LSTM记忆单元的功能),其实际上是LSTM的一种简化版本或者特殊形式。
Attention Mechanisms注意力机制,来源于神经科学和计算神经科学,基本框架是输入注意力信号和输入,通过注意力信号得到后续输入。典型实现方法有soft attention和hard attention。
深度学习模型的应用,有1.DBN的应用,基于DBN的问答对挖掘,2.CNN的应用,关系的分类,Image captioning,3.LSTM的应用,机器翻译,文本摘要。
情感分析
情感分析是什么。情感分析也叫观点抽取,观点挖掘,情感挖掘,主观分析。为什么需要情感分析:电影评论分析,产品分析,公共情感,政策,预测。Scherer关于情感状态的分类1.Emotion,2.Mood,3.Interpersonal stance,4.Attitude,5.Personality traits。情感分析就是对attitude的侦测。态度包括1.Holder,2.Target,3.态度的类型,4.包括态度的文本。情感分析的任务1.简单任务,判断文本正面还是负面,2.更加复杂的,给文本的态度打分1~5,3.高级的,检测目标,源或者复杂的态度类型。
基线算法。需要1.Tokenization,2.特征提取,3.使用不同的分类器分类,包括朴素贝叶斯,MaxEnt,SVM。Tokenization的问题是要处理HTML和XML的标记等,特征提取需要处理负面比如在负面词到标点符号之间添加NOT_标记,可以只用形容词,也可以用全部的词。分类器如朴素贝叶斯,也可以用二值化(Boolean特征)多项式的朴素贝叶斯(是否出现比出现的频率更加重要)。基线方法假设所有的类都有相同的频率,如果没有有两种解决方案1.重新采样,2.带代价的情感学习。
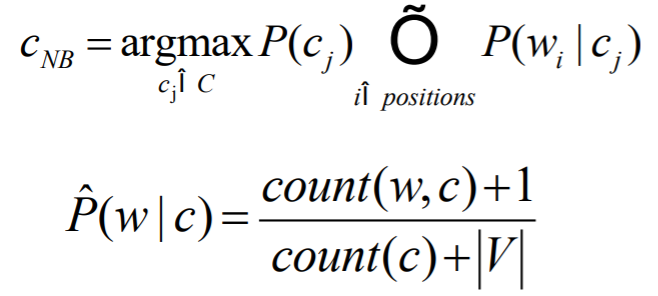
情感分析总结。大多数被建模成分类任务或者回归任务(预测二进制或者序数标签)。特点有1.负面非常重要,2.对某些任务使用所有的词(朴素贝叶斯)效果比较好,3.找到词的子集对某些任务有帮助(手动建立极性词汇表,使用种子和半监督学习来导出词汇表)。
使用CNN完成情感分析。有1.CNN-rand,2.CNN-static,3.CNN-non-static,较好,4.CNN-multichannel。
情感分析的其他任务,有1.找到观点或者属性(情感的Target),可以使用Frequent phrases加上规则,观点有可能不在句子中,可以用有监督的分类,2.在其他情感状态的计算工作,Emotion,Mood,Interpersonal stance,Personality traits,3.友善度检测。