软件构造实验三
写在前面
软件构造来取我狗命
前置知识
开闭原则
在OOP设计模式中有六大原则(点六大原则有惊喜),开闭原则是其中一个,同时也是一种非常重要的原则,对我们理解下面的工厂方法很重要。正式定义是
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
问题由来:在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。在java中这种扩展一般通过继承来实现
用一个简单的例子来说(实例来源):现在我们有一个任务是计算多片农田的面积,最开始每片农田都是矩形的,我们写出了如下代码
public class Rectangle {
private double length;
private double height;
// getters/setters ...
}
public class AreaManager {
public double calculateArea(ArrayList<Rectangle>... shapes) {
double area = 0;
for (Rectangle rect : shapes) {
area += (rect.getLength() * rect.getHeight());
}
return area;
}
}
然后按照通常的剧本,客户改需求了,出现了圆形的农田,于是我们开始改
public class Circle {
private double radius;
// getters/setters ...
}
public class AreaManager {
public double calculateArea(ArrayList<Object>... shapes) {
double area = 0;
for (Object shape : shapes) {
if (shape instanceof Rectangle) {
Rectangle rect = (Rectangle)shape;
area += (rect.getLength() * rect.getHeight());
} else if (shape instanceof Circle) {
Circle circle = (Circle)shape;
area += (circle.getRadius() * cirlce.getRadius() * Math.PI;
} else {
throw new RuntimeException("Shape not supported");
}
}
return area;
}
}
发现了问题没有,以后每当多出现一种形状,我们都要去修改AreaManager的代码。在java中,修改意味着重新做代码评审和单元测试,这是十分麻烦的事情。
让我们来用开闭原则来重新看一下这个问题。我们要能够支持扩展,并且禁止修改。我们可以定义一个叫Shape的接口,在接口里面定义我们实际需要的计算面积的方法。同时把AreaManager传入的ArrayList的参数设置为Shape
public interface Shape {
double getArea();
}
public class Rectangle implements Shape {
private double length;
private double height;
// getters/setters ...
@Override
public double getArea() {
return (length * height);
}
}
public class Circle implements Shape {
private double radius;
// getters/setters ...
@Override
public double getArea() {
return (radius * radius * Math.PI);
}
}
public class AreaManager {
public double calculateArea(ArrayList<Shape> shapes) {
double area = 0;
for (Shape shape : shapes) {
area += shape.getArea();
}
return area;
}
}
我们可以发现,在以后如果需要增加新的形状我们只需要做扩展:增加新的Shape的实现类,而不需要去修改AreaManager的源代码。这就符合开闭原则了,在某种意义上这也是java中接口的来源。
工厂模式
工厂模式是一种设计模式,他们的共同点就是都避免了直接用new来创建需要的对象,而是通过调用某个方法来创建一个对象,这样的好处是可以在使用者的层面隐藏具体类的实现细节,典型的例子是Lab2中Graph接口中的emptyInstance方法。工厂模式中一共有三个概念,静态工厂模式(简单工厂模式),工厂方法模式,抽象工厂模式,下面三个都有例子,点我跳进去
静态工厂模式,典型特征就是有一个静态方法,根据输入的参数创建不同的对象并返回给使用者
工厂方法模式和抽象工厂模式都是如下的结构,区别在于工厂接口中的方法不同
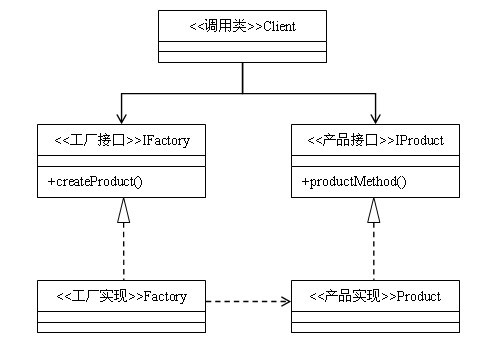
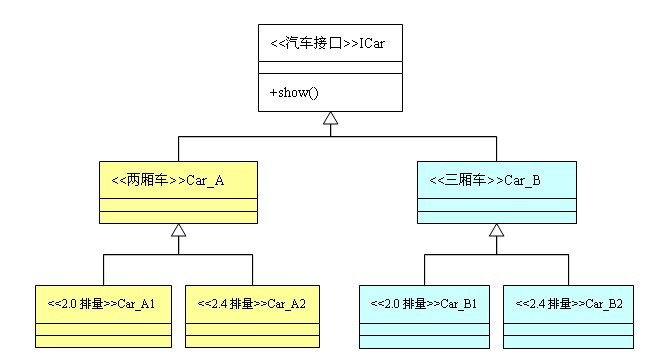
工厂方法中是返回的同一个产品等级的对象,抽象方法则返回的是产品族。同一个产品等级可以理解为是同一个接口的不同的实现类,产品族则是不同的接口的下的不同的实现类,但是这两个实现类有某些共性,如下图,其中Car_A1和Car_A2属于一个产品等级,Car_A1和Car_B1则属于同一个产品族,因为他们两个都是2.0排量的。
builder模式
点这里看原版,主要是一种构造器技术。有时候构造一个类时可选的传入参数太多,如果用重载构造器的方法来写的话太复杂并且太难读。下面例子来源
public class LoginBean {
private String id;
private int uid;
private String name;
private String mobile;
private String portrait;
private String realName;
public LoginBean(String id,int uid,String name,String mobile,Strin
portrait,String realName){
this.id=id;
//此处省略
this.realName=realName;
}
还有一种技术叫JavaBeans模式,写一个传入必要参数的构造器,然后写set方法来设置各可选参数,但是这样安全性较差,不能防止在set过程中参数发生变化
LoginBean bean = new LoginBean();
bean.setId(xxx);
//此处省略
bean.setRealName(xxx);
builder模式是在这个类中写一个内部静态类,一般名字都叫builder,构造时先造一个builder,然后用第二种方式来初始化这个builder,最后把这个builder当传入参数传进类的构造器中,具体可以见下面的例子
/*要构造的目标类*/
public class Test {
private final String id;
private final String uid;
/*builer类*/
private Test(Builder builder) {
this.id = builder.id;
this.uid = builder.uid;
}
public static class Builder {
private String id;
private String uid;
public Builder setId(String id) {
this.id = id;
return this;
}
public Builder setUid(String uid) {
this.uid = uid;
return this;
}
public Test build() {
return new Test(this);
}
@Override
public String toString() {
return "Builder{" +
"id='" + id + '\'' +
", uid='" + uid + '\'' +
'}';
}
}
@Override
public String toString() {
return "Test{" +
"id='" + id + '\'' +
", uid='" + uid + '\'' +
'}';
}
}
/*客户端代码*/
public static void main(String [] args){
Test test = new Test.Builder()
.setId("0")
.setUid("fadf")
.build();
System.out.print(test.toString());
}
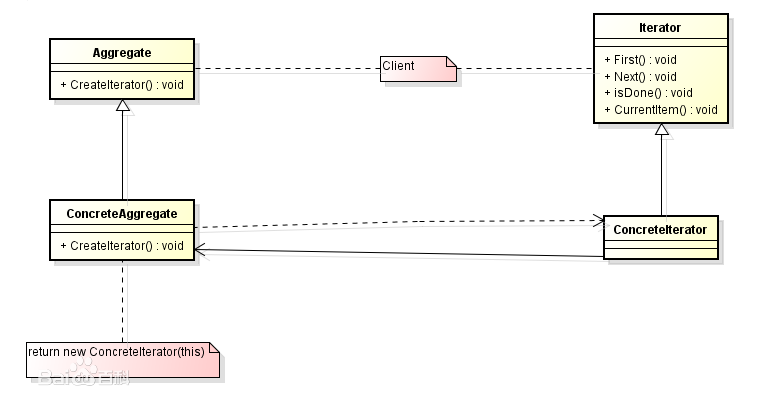
Iterator模式
点这里,说的很清楚了,有下面四个角色(模式所需要的类)。
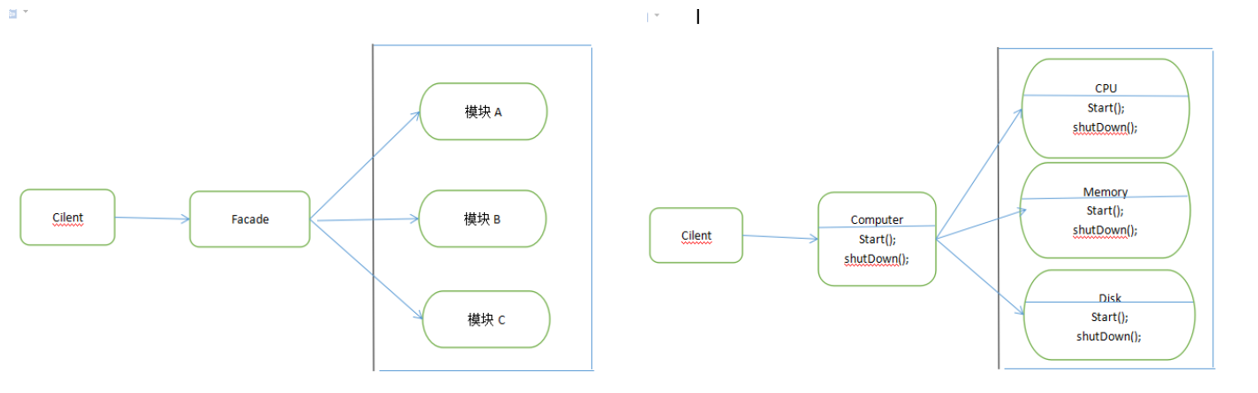
facade模式
很简单,就是把你整个系统的各项API做成一个类来给用户使用。打个比方就像下面的电脑中CPU,Memroy,和disk是你的系统的各个组件,你的电脑给用户的接口就只能有开机关机等功能,这时你就要做一个叫Computer的Facade类来提供给用户。在大型系统的开发中有可能出现多级facade类。
strategy设计模式
strategy设计模式就是利用多态特性(接口等),具体点这里
decorator设计模式
目标是能支持动态地给一个对象添加一些额外的职责(用人话说就是要给一个类增加一个方法)。就增加功能来说,Decorator模式相比生成子类更为灵活,可以根据运行时的需要决定加多少东西,更详细戳这里(带例子)。
抽象构件类(Component):给出一个抽象的接口,用以规范准备接收附加责任的对象
具体构件类(ConcreteComponent):定义一个具体的准备接受附加责任的类,其必须实现Component接口。
装饰者类(Decorator):有一个构件(Conponent)对象的成员变量,并定义一个和抽象构件一致的接口(我们就是通过这个一致的接口中的东西来加东西)。
具体装饰者类(Concrete Decoratator):定义给构件对象“贴上”附加责任。
每次想给具体构建类的某个实例加上一点东西的时候,我们做出要加上的东西对应的具体装饰者类,以具体构建类作为构造器的输入参数,然后调用装饰类的方法输出装饰后的结果。注意上述所有的变量的声明都是他们的公共接口。
state设计模式
具体例子点我
状态模式所涉及到的角色有:
环境(Context)角色,也成上下文:定义客户端所感兴趣的接口,并且保留一个具体状态类的实例。这个具体状态类的实例给出此环境对象的现有状态。
抽象状态(State)角色:定义一个接口,用以封装环境(Context)对象的一个特定的状态所对应的行为。
具体状态(ConcreteState)角色:每一个具体状态类都实现了环境(Context)的一个状态所对应的行为。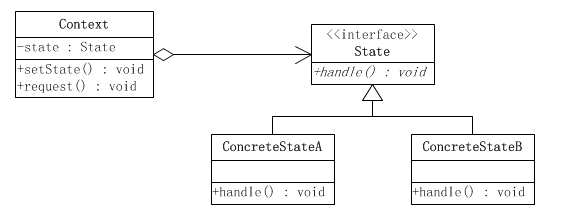
memento备忘录模式
Originator发起人角色:记录当前时刻的内部状态,负责定义哪些属于备份范围的状态,负责创建和恢复备忘录 数据。
Memento备忘录角色:负责存储Originator发起人对象的内部状态,在需要的时候提供发起人需要的内部状态。
Caretaker备忘录管理员角色:对备忘录进行管理、保存和提供备忘录。
//发起人角色
public class Originator {
//内部状态
private String state = "";
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
//创建一个备忘录
public Memento createMemento(){
return new Memento(this.state);
}
//恢复一个备忘录
public void restoreMemento(Memento _memento){
this.setState(_memento.getState());
}
}
//备忘录角色
public class Memento {
//发起人的内部状态
private String state = "";
//构造函数传递参数
public Memento(String _state){
this.state = _state;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
}
//备忘录管理员角色
public class Caretaker {
//备忘录对象
private Memento memento;
public Memento getMemento() {
return memento;
}
public void setMemento(Memento memento) {
this.memento = memento;
}
}
//场景类
public class Client {
public static void main(String[] args) {
//定义出发起人
Originator originator = new Originator();
//定义出备忘录管理员
Caretaker caretaker = new Caretaker();
//创建一个备忘录
caretaker.setMemento(originator.createMemento());
//恢复一个备忘录
originator.restoreMemento(caretaker.getMemento());
}
}
checkStyle
别紧张不是什么设计模式,是个静态代码风格的检查工具。因为在实验五中要用这个改风格,我就看了看。在eclipse里面安装checkStyle的教程点我,安装完之后测试lab2的项目发现我的风格需要改的地方如下图黄色所示
我本来是直接右转开窗跳楼一条龙的。但是!Eclipse有Ctrl+Shift+F这个可以自动格式化代码的快捷键,我们是不是可以搞到这个checkStyle的编码规范,然后设置为Ctrl+Shift+F的格式化文件,那实验五中大量的修改风格的工作变成了按Ctrl+A和Ctrl+Shift+F。还能再爽一点吗???
实际上是有这种东西的。在eclipse设置(Perference)里面可以看到checkStyle是复制了Google的风格,我们就去Google的GitHub上面去翻,然后把xml文件搞到并设置为格式化程序的文件就好了。具体操作:1.点我跳Google的风格文件 2.Ctrl+A复制下来,保存为eclipse-java-google-style.xml 3.打开eclipse的格式化程序(英文的Eclipse应该在Java-CodeStyle-Formatter那里,看下面图) 4.新建一个风格,然后导入你刚刚保存的xml文件,点应用,再按Ctrl+A和Ctrl+Shift+F试试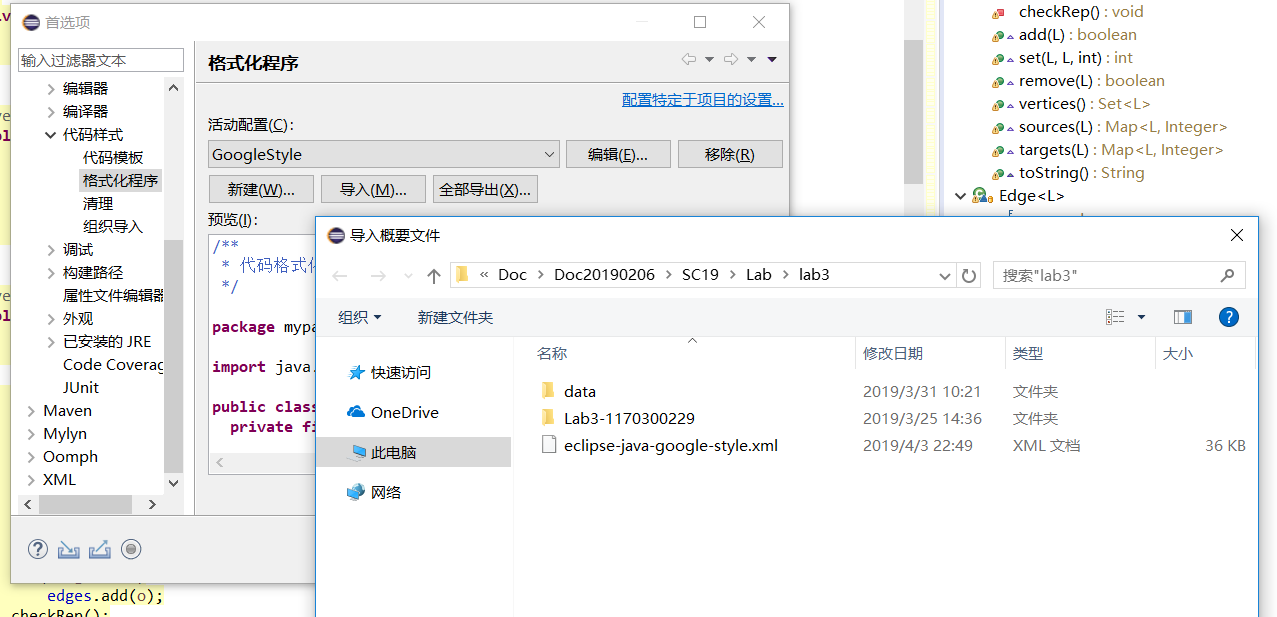
SpotBugs
这也是个静态代码检查的工具,用来检测你代码中潜在的bug,具体安装教程点我,要翻到下面的Eclipse部分看。
实现
整个项目的架构大致像下面那样,最顶层的接口是CircularOrbit,其中规定了实验要求的方法,以及获得内部表示的一些方法。而在最后的app中,我们实际上是创建了三个具体的应用来完成我们需要的功能。Track是对轨道的抽象,Graph是对关系网络的抽象。Track其实也是个接口,其中有具体的实现类,而不同的Track实现类实际上用于不同的应用。但在ConcreteCircularOrbit中我们依然是面对Track接口编程的。Graph则直接沿用了lab2中的graph,但是将边权改成了Double,并且增加了查找距离的方法。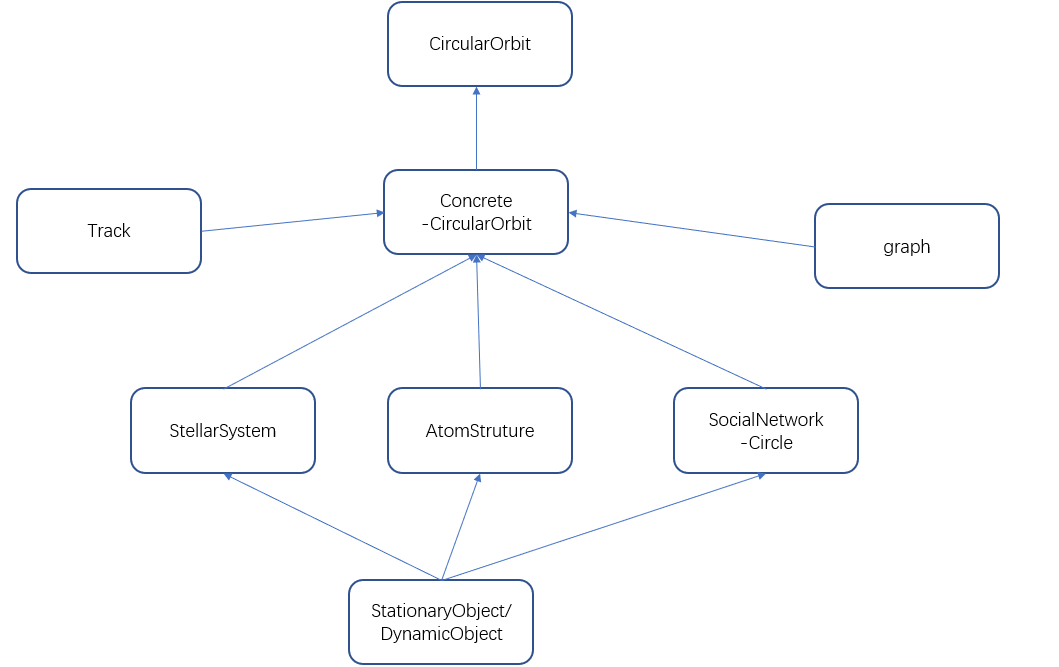
下面的包结构的图很好地说明了————我是真的不想画类图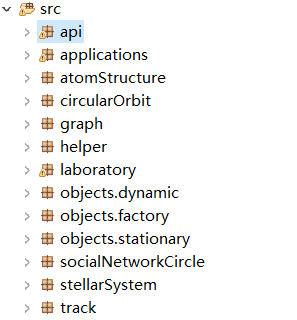
由于细节实在是太多,且具有很强的针对性,因此我不打算在这里描述这些细节。具体见实验报告(以后会放上来的)。但是其中对熵的计算值得提一下,实际上计算模型来源于将n个相同的物体放入到m个不同的盒子中并结合信息熵的定义。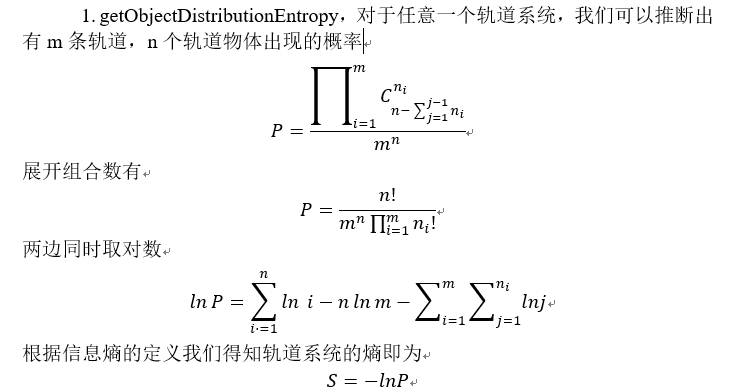
泛型实际上是类型擦除,泛型类和泛型方法的时候都是在声明的时候同时声明泛型,并且在内部使用定义的泛型。具体的说明点我。其中值得注意的是泛型通配符’?’的使用,通过super和extend可以限定匹配的类型的范围。泛型的好处当然是提高了复用性,能够适应更多的应用环境。坏处是减少了泛型类内部的泛型对象的使用功能(即可调用的方法),因为被定义为泛型的类型的变量实际上是不知道他所能拥有的方法的。泛型是不存在子类替换父类的原则的。例如一个方法中如果定义传入的参数是Generic\<Map>,那么是不能传入一个Generic\<HashMap>的,这也正是通配符’?’存在的意义。另外创建泛型对象组成的数组时也可能需要用到通配符,详见链接。常用的泛型的一些例子见下面。
//泛型类
//子类在继承泛型类的时候可以指定泛型的具体类型
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{
private 泛型标识 /*(成员变量类型)*/ var;
.....
}
}
public class Generic<T>{
//key这个成员变量的类型为T,T的类型由外部指定
private T key;
public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定
this.key = key;
}
public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定
return key;
}
}
public static void main (String args[]) {
//泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
//传入的实参类型需与泛型的类型参数类型相同,即为Integer.
Generic<Integer> genericInteger = new Generic<Integer>(123456);
//传入的实参类型需与泛型的类型参数类型相同,即为String.
Generic<String> genericString = new Generic<String>("key_vlaue");
Log.d("泛型测试","key is " + genericInteger.getKey());
Log.d("泛型测试","key is " + genericString.getKey());
}
//泛型接口
public interface Generator<T> {
public T next();
}
/**
* 传入泛型实参时:
* 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator<T>
* 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
* 在实现类实现泛型接口时,如已将泛型类型传入实参类型
* 则所有使用泛型的地方都要替换成传入的实参类型
* 即:Generator<T>,public T next();中的的T都要替换成传入的String类型。
*/
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}
//泛型方法
/**
* 泛型方法的基本介绍
* @param tClass 传入的泛型实参
* @return T 返回值为T类型
* 说明:
* 1)public 与 返回值中间<T>非常重要,可以理解为声明此方法为泛型方法。
* 2)只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
* 3)<T>表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
* 4)与泛型类的定义一样,此处T可以随便写为任意标识
* 常见的如T、E、K、V等形式的参数常用于表示泛型。
* 5) 如果拥有此方法的类也是泛型并且也声明了泛型T的时候
* 在此方法中的T将是定义在方法处的T,而不是类的泛型T
*/
public <T> T genericMethod(Class<T> tClass)throws InstantiationException ,
IllegalAccessException{
T instance = tClass.newInstance();
return instance;
}
关于可视化,这里采用的是java中自带的awt和swing。在awt的体系中JFrame负则窗口的绘制,JPanel相当于安装在窗口上的面板,能够在上面安装部件component或是通过Graphics绘图,也可以直接在JFrame上绘图。在这里可以直接用Graphics绘图而不需要关心layout或是其他部件的安装。
具体的操作方法是通过继承JFrame/JPanel,然后重写paint函数,利用其中的Graphics的方法来直接画画。其中Graphics有一种Graphics2D的类可以干很多神奇的事情,具体教程点我
// 抗锯齿化
((Graphics2D) g).setRenderingHint(RenderingHints.KEY_ANTIALIASING,
RenderingHints.VALUE_ANTIALIAS_ON);
//画虚线,可调参数
float[] dash = new float[] {5, 10};
BasicStroke bs2 =
new BasicStroke(1, BasicStroke.CAP_SQUARE, BasicStroke.JOIN_MITER, 10.0f, dash, 0.0f);
((Graphics2D) g).setStroke(bs2);
动画则一定要继承JPanel,直接继承JFrame会出现严重的闪烁现象,是因为JPanel有一种叫双缓冲的技术,能够很好的解决闪烁。而JPanel中是默认使用的。具体做法我是参考这里的(点我)。在上面那个网址中作者继承的是JFrame,我不知道他怎么解决闪烁的问题的…绘制动画的原理很简单就是每隔一段时间就更新画面(在实验里是更新行星的位置)并重画。需要自己定义一个新的线程类并且在构造JPanel的时候开启这个新的线程。在自己定义的线程中sleep一段时间后在调用repaint。这里可以通过重写update方法(repaint实际上会调用的方法)来每次只重画行星从而提高重画的速度。注意有关repaint详细的细节点我
// 继承的JPanel的构造函数
public StarPanel(StellarSystem inputOrbit, boolean centerNameOn, boolean objectNameOn) {
orbit = inputOrbit;
centerName = centerNameOn;
objectName = objectNameOn;
new PaintThread().start(); // 在构造的时候就开启新的线程
}
//自定义的线程
class PaintThread extends Thread {
@Override
public void run() {
for (;;) {
repaint();
try {
Thread.sleep(4);
nowTime += (1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
电子结构的可视化
社交网络的可视化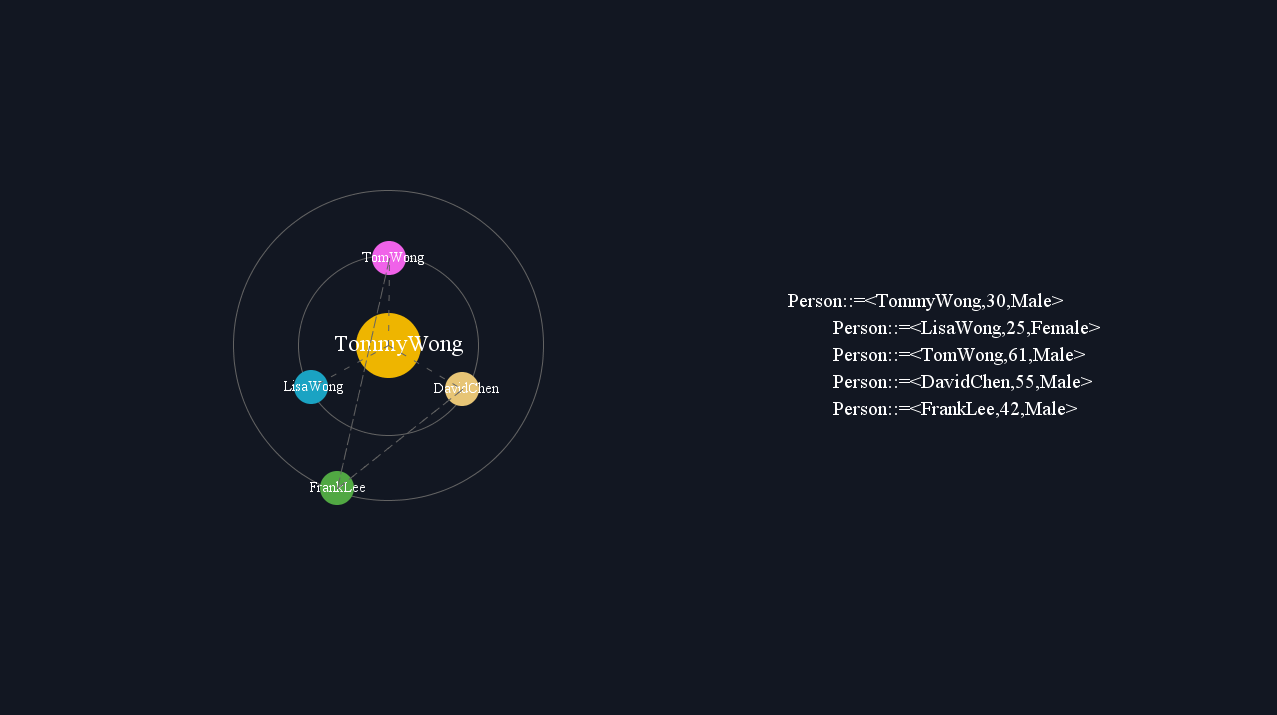
放一张太阳系
最后记录一点想法。在项目中尽可能限制mutable的范围,例如不再Track中记录轨道物体,因为这会让Track变成mutable,而是在CircularOrbit来建立轨道物体和Trakc的对应关系,这样就将Track变为immutable。限制mutable将大大提高项目的可靠性,以及修改的代价。项目中最考验的应该是类结构和每个类的功能的设计。这非常依赖对抽象层次的理解。有时候会出现面对一个接口/父类但是需要其具体的实现类/子类的功能,这就是抽象层次的设计的问题。不同的客户端面对的抽象层次不一样,需要创建的对象也不一样。更加具体的客户需要创建抽象树中更具体的子类,而更加抽象的客户端则更多地面对接口或是父类。合适的抽象层次的设计会让每一个客户都找到自己需要的层次而不是过多地通过组合或是其他手段制造一个自己需要的对象。抽象树应当具有类似开闭原则的特征,即可以很容易地扩展出更加具体的子类,不需要修改高层的抽象结构。